
データ処理基盤構築プラクティス
Overview
本記事ではデータプラットフォームを構築するのに考慮の必要なポイントについてまとめた。
データプラットフォームに関わる基本的な概念に関してはデータ処理基盤に関わる基本概念で触れている。
データパイプラインの構築
データ処理基盤のパイプライン構築には下記のようなステップを踏む
- データ収集
- DWH 作成
- データマート作成
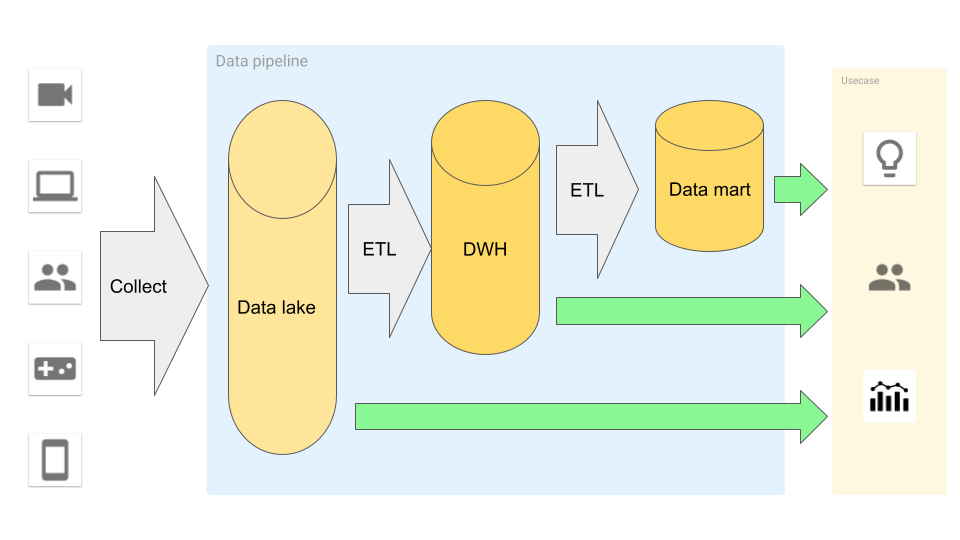
データ収集
データレイクを構築する為にはデータソースからデータを収集する必要がある。 データソースは色々な形式が考えられ、RDB である場合や CSV, API, 外部の Web サイトをスクレイピングする場合もあり、データソース毎にそれぞれデータ収集の形式が異なる。
データ収集において気にするポイント
- 負荷
- DB にクエリを発行する場合に負荷が高まらないか。深夜のユーザーが利用しない時間帯に行うべきか、Read Only などマスタ以外のインスタンスを使うべきか
- API の連続呼び出し負荷
- Web サイトの更新負荷
- PII 1
- PII は含むべきか、マスキングするべきか
ファイルデータ
CSV や s/s などのデータの取り込み
- ファイルの更新通知を設けることでファイルの作成過程などでの誤読み取りを防ぐ
- GCS などのオブジェクトストレージを用い、トリガー機能を利用すると良い
- ファイル内の構造が変わる可能性がある場合にはカラムなどの情報を持つメタデータを別途用いる
- AVRO を用いるとデータの型などを厳密に定義できる
- JSON などと違いデータの中身を確認しづらいというデメリット
データのサイズに注意する
- JSON はキーをすべて保持する必要がある
- CSV はキーを毎回書く必要がないため JSON と比べてデータ量が少なくなる
- データ量を減らしたい場合は Parquet を用いると良い
- データをテキストでなくバイナリで表現
- 列指向でデータを圧縮
- 高効率なカラム単位の圧縮と、異なるデータの種類の列に対応する柔軟な符号化方式を採用
- BigQuery などは gzip などで圧縮したデータを読み込める
API
API を通したデータの取得に関して。
- 一定期間の実行回数、Quota に注意する
- API Key の期限切れに注意する
データベース
データベースを利用したデータ取得に関して。
- データサイズが大きい場合は fetch や、limit & offset などを利用する
- 更新データの データレイク・DWH 内での取り扱いに注意する
- DWH を扱うようなプロダクトは更新処理が苦手な場合が多い。一時保存先を設けて上書き更新するなど工夫が必要な場合がある
データ取得のアプローチ
- SQL
- SQL でデータを直接抽出
- 扱うデータ量やクエリ次第では負荷が高まる
- エクスポート
- データをファイルにエクスポートしてファイルからデータを取得
- DB 負荷を抑えられる
- データサイズが大きくなりがち
- ダンプファイル
- バイナリ形式のためデータサイズが抑えられる
- 復元用の DB が必要
- 本番 DB には負荷を与えない
- 更新ログ
- MySQL でいうバイナリログなどの更新ログを利用する
- 復元用 DB に取り込む
- 収集するデータ量が少なくなるのが最大のメリット
- 仕組みの構築が複雑になるのがデメリット
- MySQL でいうバイナリログなどの更新ログを利用する
ログ
ログを利用したデータ取得に関して。
ログからは以下のような情報が取得できる。
- アクセス先 URL
- アクセス時間
- リクエスト内容
- ユーザーエージェント
- アプリケーションの文脈を含む情報
ログ情報収集のアプローチとしては以下の選択肢がある。
- アプリケーション Log を普通に出力しログの処理ツールからデータレイクに流し込む
- GCP なら Cloud Logging -> Log Sink -> GCS / BigQuery のような形
- アプリケーション側でメッセージキューに対して必要な情報だけ出力する
- Application -> Pub/Sub -> (Dataflow) -> GCS / BigQuery のような形
データレイク構築
- データを加工せずそのまま保存する
- データ損失を防ぐ
- 機密情報や個人情報は必要に応じてマスキングを行う
データの保存方針
- ファイルはオブジェクトストレージに置く
- ライフサイクルを導入し過去のものはティアを下げ利用料金を抑えるなどする
- 圧縮しファイルサイズを抑える
- CSV や JSON は DB に入れる事も選択肢に入る
- BigQuery などは JSON を扱うのも得意
DWH 構築
- 行指向の RDB ではなく 列指向の DB の方がデータ抽出・集計に向いている
- 自分は現状 BigQuery 一択
- 列指向の DB は更新などは不向き(出来ないものも有る)ので運用は気をつける
大量データの分散処理
データレイクや DWH から ETL を行う場合には大量のデータを扱うことも珍しくない。 複数マシンを用いてスケールアウトしやすい Spark や Flink 、 GCP であれば Dataflow を用いてスケーラブルなアプローチで分散処理を行う。
パイプライン構築時には予め分散処理を前提にしておくと良い。 最初はデータ量が少なく必要がないかもしれないが、予め大規模分散処理を行いやすいアーキテクチャで構築すると少量のデータも扱え、後々データが増えた場合にも簡単に対応できる。
アーキテクチャ
データ処理基盤を構築するための代表的なアーキテクチャ
ラムダアーキテクチャ
バッチ処理(バッチレイヤー)とストリーム処理(スピードレイヤー)に分けてデータを処理する。
- バッチレイヤー (コールドパス) は、すべての受信データを未加工の形式で保存し、データに対してバッチ処理を実行する。 処理の結果はバッチビューとして保存される
- スピードレイヤー (ホットパス) では、リアルタイムでデータを分析する このレイヤーは、精度と引き換えに待機時間が短くなるように設計されている
- バッチレイヤーは効率的なクエリのためにバッチビューにインデックスを付けるサービスレイヤーにフィードし、スピードレイヤーは最新のデータに基づく増分更新でサービスレイヤーを更新する
カッパアーキテクチャ
ラムダアーキテクチャと基本的な目標は同じだが、ストリーム処理システムを使用してすべてのデータが単一のパスを経由するという違いがある。 ラムダアーキテクチャは 2 つの異なる場所をデータが通るため計算ロジックが複雑になるのが課題だったが、それを解決した。
参考
- 実践的データ基盤への処方箋〜 ビジネス価値創出のためのデータ・システム・ヒトのノウハウ
- ビッグ データ アーキテクチャ
- Converging Architectures: Bringing Data Lakes and Data Warehouses Together
- データレイクとしての Cloud Storage
Footnotes
-
Personally Identifiable Information、 個人情報 ↩