
Data Lakehouse を理解する
Overview
本記事では Data Lakehouse という概念についての調査メモ。 Lakehouse は Databrics が提唱している概念のようで、特定のベンダーが進めている話ならまだ重要視するほどでもなさそうだが 論文としても出ており、 GCP でも紹介され(2021-10-29, 2022-04-05)、 つい最近発表された BigLake というプロダクトが作られる元となった考え方のようなので 2022-04 時点で Lakehouse はどういったものを指しどんな課題を解こうとしているのかということを整理する。
TL;DR
- これまでのデータ処理基盤は以前触れた通り、Datalake -> Data Warehouse(DWH) -> Datamart のようなアーキテクチャが一般的
- 従来の DWH や Datalake では分析や機械学習を行うためにはそれぞれ一定の制限がある
- Data Lakehouse は DWH や Datalake の良い点を活かして既存の制限を解決するアプローチ
本記事では論文 Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics (Ref1) での議論をベースに整理する。
従来のデータ分析基盤について
従来のデータ活用においては RDB などから必要なデータを取り出して構造化データを DWH として取り込む形が早くから始まった。
DWH は BI アプリケーションから扱いやすいが、 ML でのデータ活用ではテキスト、画像、動画、音声などの非構造化データを扱う需要があり、 DWH でのデータの持ち方では扱いづらい場面がある。
そこで、生データを扱い非構造化データの保持も可能なものとして Datalake という層を作り、非構造化データを扱う処理は Datalake を利用することで処理が可能となった。 しかし、Datalake はデータの管理が複雑で、トランザクション、データ品質の保証・一貫性・分離性などが欠如しており、データ処理パイプラインにおいてデータの追加と読み取りの同時実行などが難しいという制限がある。
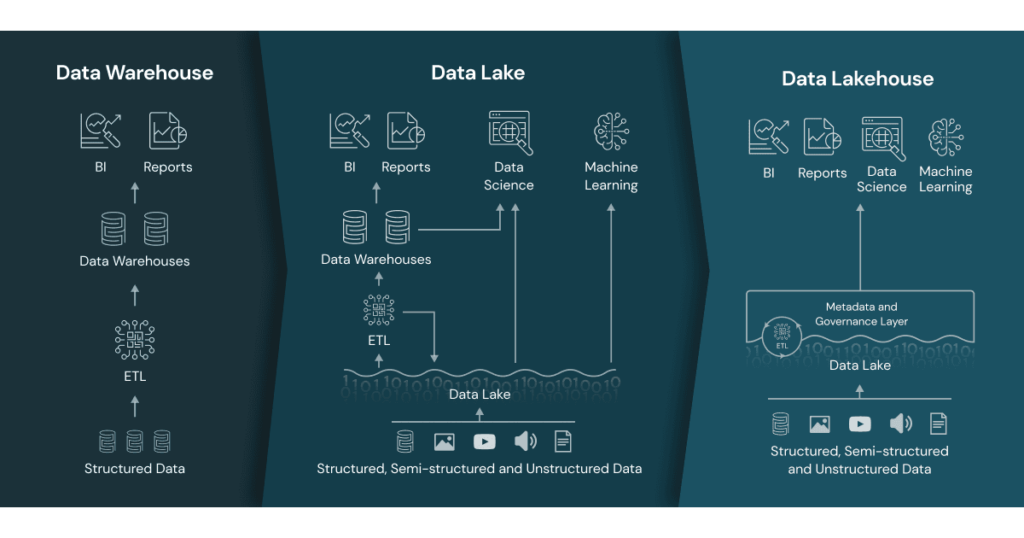
(Ref2 より)
従来のデータウェアハウスアーキテクチャの課題
- DWH は構造化データの利用には良いが非構造化データの利用には向いていない
- 機械学習を行う場合非構造化データを用いる場合もあるため DWH だけでは不十分
- 生データが前提の Datalake の概念によりではあらゆるデータを保持できるようになったが、データ処理パイプラインの作り方に制限がある
- トランザクションは管理できない
- データ品質の保証の仕組みは無視されがち
- データの重複など
- 異なる DWH にデータが有る場合にデータの移動が必要となる
- Datalake と DWH を分離したアーキテクチャでの複雑性
- それぞれでセマンティクスの異なるデータタイプ
- SQL の方言の違い
- データのスキーマが異なる
- データの鮮度
Lakehouse
Lakehouse の目指すもの
Lakehouse は、Datalake と Data Warehouse の優れた部分を組み合わせた、新しくオープンなアーキテクチャである。標準化されたシステムによって実現され DWH と同様のデータ構造とデータマネジメント機構を備えており、 Datalake のように安価なストレージに直接アクセスすることができる。
- Datalake において信頼できるデータマネジメントが可能
- Datalake のレイヤーにおいてもトランザクションや ID の管理が可能
- ML とデータサイエンスをサポート
- ML の仕組みがファイルの直接読み込む事が可能
- DataFrames のようにデータを抽象化して操作が可能
- SQL のパフォーマンス
- Parquet や ORC のようなデータフォーマットを扱える
- 直接データアクセス可能
Lakehouse が持つべきと考えられる機能
- トランザクションのサポート
- 同時にデータの読み書きを行うデータパイプラインを許容するため ACID トランザクションをサポートし、特に SQL を用いたケースで複数のデータの読み書きがあったとしても一貫性の維持が可能
- スキーマ適用及びガバナンス可能
- スタースキーマ、スノーフレークスキーマのようにデータウェアハウスのスキーマアーキテクチャをサポートすることでレイクハウスはスキーマの適用・進化をサポート
- システムはデータの完全性を保証し、頑健性のあるガバナンス機能や監査機構が可能
- BI のサポート
- ソースデータに直接アクセスして BI が可能で、遅延を減らしデータの鮮度が保つ
- データレイクとデータウェアハウスでデータの二重持ちする必要が無いためコストを低減
- 計算リソースとストレージの分離
- ストレージと計算リソースが異なるクラスターを用いることで同時接続ユーザー数の増加やデータ量の増加に応じてシステムをスケールアウト
- オープンなストレージフォーマット
- 使用するストレージフォーマットは Parquet のようにオープンかつ標準化されたもの
- TensorFlow や Spark MLlib は Parquet を読むことができるため、メタデータにクエリしどの Parquet ファイルを読むかの管理を行うだけで良い
- 機械学習、Python/R ライブラリのように多くのツールやエンジンに対する API を提供しデータへの直接アクセスが可能
- 使用するストレージフォーマットは Parquet のようにオープンかつ標準化されたもの
- 様々なデータタイプをサポート
- 画像、動画、音声、準構造化データ、テキストを含む、新たなデータアプリケーションで必要となる様々なデータタイプの分析・精錬・格納に利用
- 様々なワークロードをサポート
- データサイエンス、機械学習、SQL や分析に対応
- 全て同じデータリポジトリを使用
- エンドツーエンドのストリーミング
- ストリーミングのサポートによりリアルタイムデータ処理専用のアプリケーションを別に持つ必要がなくなる
Lakehouse のアーキテクチャ
Lakehouse は低コストで直接アクセス可能なストレージに基づくデータ管理システムであり、ACID トランザクションやインデックスなど従来の分析型 DBMS の管理・パフォーマンス機能も備えるようにしたい。 データの直接アクセスが可能なためデータの独立性は放棄する。
データはオブジェクトストレージ上で Parquet のような標準化されたフォーマットで持ち、トランザクションのサポートのためにメタデータレイヤーを持つ。 DataFrames を利用できる API を持つことで R や Python の Pandas との連携が簡単にでき、また Spark SQL では宣言的に利用でき遅延実行できる。
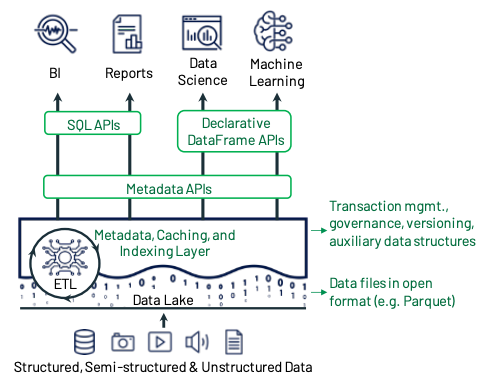
データ管理のためのメタデータレイヤー
Lakehouse として最初に必要になるの Datalake ストレージのためのはメタデータレイヤーである。 具体的には、Apache Iceberg や Apache Hudi、Delta Lake などの ファイルストレージ上に保存された Parquet/ORC フォーマットのファイルの管理を可能にするメカニズムを用いて、ACID トランザクションやバージョン管理などを可能にする。
この領域は比較的新しく、今後更に最適化が進む可能性がある。挙げられたフレームワークもトランザクションログは 1 テーブルのみをサポートしているなど、高遅延であったり、ファイルが大きくなるといったオブジェクトストレージの制限の影響を受けている。
Lakehouse における SQL パフォーマンス
Datalake における最も大きな技術的な課題は、データの独立性を放棄した(直接アクセス可能なファイルで管理するため)上でどの様に SQL の最高のパフォーマンスを実現するのかという点である。
SQL パフォーマンスを良くするアプローチとしては以下が考えられる。
- Caching
- トランザクションのメタデータを処理ノードの SSD や RAM に置く
- 補助データ
- カラム毎の最大最小値の統計情報を各ファイルごとに持つ
- Bloom filter ベースのインデックスを構築し選択した列でデータをスキップできるようにする
- データの配置
- Z-order1 などを用いてデータの局所性を表現する
直接アクセス可能で長期的にデータの保存が可能かつ高パフォーマンスな Lakehouse の仕組みの設計は現状も課題である。 将来的にはこのユースケースに特化した新たなデータフォーマットの自体が必要かもしれないが、それを抜きにしてもここで上げたパフォーマンスを良くするための要素はいずれも向上の余地はある。
クラウドベンダーにおける Lakehouse
BigLake - GCP
Lakehouse の調査をするきっかけになったのは Apr2022 の Google Data Cloud Summit 先駆けて BigLake についての記事が発表されたからだった。
記事の執筆時点では Preview 版であるが、 Introduction to BigLake tables に BigLake の説明がある。
簡単に表現すると BigLake は BigQuery External Table 機能の拡張のようなものだ。
基本的には BigQuery (以下 BQ) をインターフェイスとして、GCS や S3 などのオブジェクトストレージへアクセスするが、BQ がアクセスマネジメントを抽象化する。
つまり、ユーザーのアクセス権限は BQ のテーブルに対してのみ考えたら良く、BQ を超えたレイヤー(i.e. 外部のストレージ)に対するアクセス権限をユーザーは意識する必要がない。

(Ref4 より引用)
現状はトランザクションへの言及などはなく、非構造化データとの連携もこの形で行いやすくなるとも思えないため、自分の理解ではこれまで触れてきた Lakehouse の目標には届いていない印象。 BQ の場合はそもそも Dataflow や Serverless Spark 等の ETL のレイヤーから低遅延の Storage API を提供してデータを素早くよしなに扱って欲しいという思惑があるかもしれない。
また、BQ はトランザクションのサポートが Preview レベルではあるが開始されているため、 今後外部テーブル関しての操作自体2やトランザクション機能の追加があると Lakehouse の実現に近づくと思う。
Dataproc の新しいテーブル形式を使ってみるや How to build an open cloud datalake with Delta Lake, Presto & Dataproc Metastore などの記事にもある通り、 GCP 上での Delta Lake や Apache Iceberg の利用も可能だが、Dataproc (i.g. Hadoop) で Spark の利用が前提になっている。 Spark/Hadoop クラスタの運用は手間がかかるので、Serverless Spark が GA とったことはこれらのフレームワークを利用する上でも良い発展に思える。
Delta Lake - Azure
Azure は Databrics と連携しており、Delta Lake についての厚めのドキュメントがある。
日本語で細かく説明したドキュメントは貴重なので一読の価値あり。
(Ref6 より引用)
AWS
AWS では Build a Lake House Architecture on AWS、 Harness the power of your data with AWS Analytics、 How to Accelerate Building a Lake House Architecture with AWS Glue など、AWS 上で Lakehouse を構築する方法を説明した記事が多く見つかった。
中でも AWS Lake Formation は Lakehouse 構築のためのキーとなるプロダクトに見え、S3 のファイルに対して ACID トランザクションを実現したりクエリによるアクセス速度の向上を実現でき、 論文中で言及していたデータ管理のためのメタデータレイヤーを構築を可能にする。
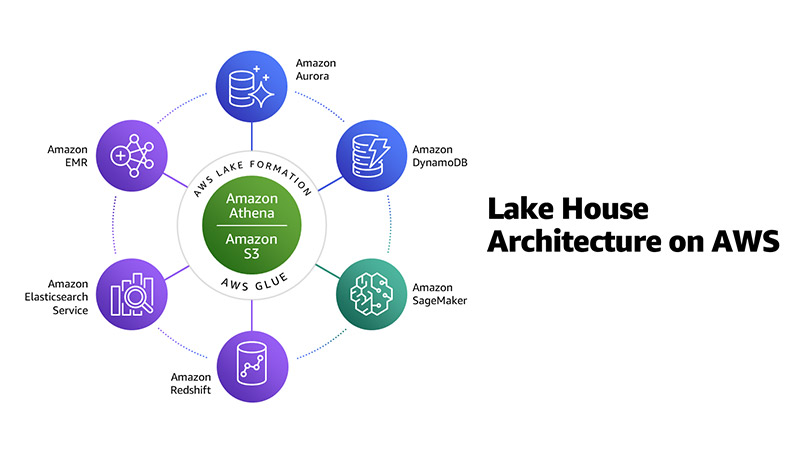
(Ref9 より引用)
 (Ref10 より引用)
(Ref10 より引用)
終わりに
本記事では Data Lakehouse の調査を行った。
Lakehouse は従来の DWH や Datalake の仕組みに存在した制限を乗り越えるためのアプローチである。
Datalake は ACID トランザクションやインデックス等の DBMS のような仕組みを用いていたり、Parquet/OCR のような標準化されたファイルフォーマットを用いての直接ファイルアクセスが可能なことが期待される。
各クラウドベンダーもそれぞれ Lakehouse に言及しており、今後のデータ処理基盤構築では意識していくべきものに思える。 Lakehouse の実現には Dalta Lake のようなフレームワークを用いるか、各クラウドベンダーが提供するプロダクトを用いると良さそうだが、ベンダー毎に実現可能なレベル感はまだ一定ではなく、今後の継続的なアップデートが期待される。
References
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
- What Is a Lakehouse?
- Rise of the Data Lakehouse in Google Cloud
- Introduction to BigLake tables
- BigLake: Unify data warehouses and lakes with Google Cloud
- Databricks Data Science & Engineering とは
- Delta Engine および Delta Lake ガイド
- Build a Lake House Architecture on AWS
- Harness the power of your data with AWS Analytics
- How to Accelerate Building a Lake House Architecture with AWS Glue
Footnotes
-
余談だが私の修士の研究では Z-order で局所性を考慮したアプローチをしていたので思い入れがある ↩